Les systèmes de mémoire LLM oublient exactement comme les humains, avec les mêmes chiffres que les expériences les plus répliquées de la psychologie clinique. C'est la thèse centrale du travail d'@ashwingop, et elle n'est pas métaphorique.
Ce qui est en jeu : la fiabilité de chaque RAG system, chaque vector database, chaque semantic search que tu as en production aujourd'hui.
L'illusion dimensionnelle
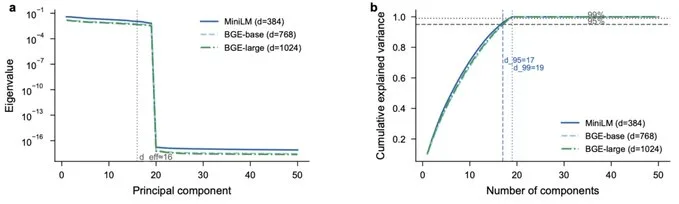
Quand tu choisis un modèle d'embedding, tu regardes sa dimensionnalité. 384 pour MiniLM, 768 pour BGE-base, 1024 pour BGE-large. L'intuition est que plus de dimensions signifie plus de capacité à distinguer des concepts, donc moins d'interférence entre tes documents.
@ashwingop et son équipe ont mesuré le "participation ratio" de ces trois modèles en production, c'est-à-dire le nombre de dimensions qui portent réellement de la variance significative. Les résultats :
Dims effectives◆
15.7
MiniLM, 384 nominales
Dims effectives◆
16.6
BGE-base, 768 nominales
Dims effectives◆
16.3
BGE-large, 1024 nominales
17 à 18 composantes principales suffisent pour expliquer 95% de la variance, quelle que soit la dimensionnalité nominale du modèle. Tripler la taille de l'embedding laisse le nombre de dimensions utiles scotché à 16.
La conclusion d'@ashwingop est chirurgicale : "A model that claims to be 1,024-dimensional but concentrates its variance in 16 is not providing 1,024 dimensions of protection against interference. It is providing 16."
Ce phénomène, ils l'avaient déjà observé dans les KV cache de transformers avec SpectralQuant : d_eff ≈ 4 sur 128 dimensions dans les key vectors des attention heads, soit 3.1% de l'espace nominal. Là-bas, cette concentration était une opportunité qui leur a permis de battre TurboQuant de Google de 18.6% sur la compression. Dans les embedding spaces, la même concentration est une vulnérabilité. Même géométrie, implications opposées.
Pourquoi ton RAG oublie et invente
La concentration spectrale explique deux pathologies que tu as probablement observées en prod sans pouvoir les nommer.
L'oubli power-law. La courbe d'Ebbinghaus, documentée en 1885, dit que la mémoire décline selon une loi de puissance avec le temps. Pendant 140 ans, deux théories s'affrontent sur le mécanisme : la théorie du déclin (les traces mémorielles s'effacent avec le temps) et la théorie de l'interférence (elles se font écraser par les concurrentes).
@ashwingop a testé les deux sur 1000 faits encodés sur 30 jours simulés.
La réponse est tranchée : "Remove the competitors and the forgetting exponent drops fifty-fold." L'oubli dans les embeddings vient de la compétition entre mémoires dans un espace à faible dimensionnalité effective. Supprime les concurrents, l'oubli quasi-disparaît.
Les faux souvenirs. Le chiffre est franchement inconfortable. "False memories require no engineering. Raw cosine similarity on unmodified pre-trained embeddings reproduces the classic false memory rate (0.583 vs human ~0.55) with zero parameter tuning."
La cosine similarity brute sur des embeddings pré-entraînés non modifiés génère un taux de faux souvenirs de 0.583. Les humains sont à ~0.55. Ton RAG est légèrement pire qu'un humain sur ce point, sans que tu aies fait la moindre erreur d'implémentation.
Ce que le cerveau fait mieux (et pourquoi c'est instructif)
Le cortex biologique opère à des dimensionnalités effectives estimées entre 100 et 500, d'après les enregistrements neuronaux. C'est 6 à 30 fois plus que MiniLM ou BGE-large. Le cerveau se situe dans une zone de transition où l'interférence devient non-négligeable mais reste gérable, ce qui correspond exactement au compromis que l'évolution a optimisé.
Nos embeddings de production sont coincés à 16 dimensions effectives, bien en dessous de cette zone.
La conclusion qu'@ashwingop en tire repositionne complètement le problème : "The boundary between biological and artificial memory is thinner than anyone assumed." Et plus fondamentalement : "Forgetting and false memory are not bugs of biological hardware. They are features of any system that organizes information by meaning and retrieves it by proximity."
L'oubli et les faux souvenirs sont des propriétés géométriques de tout système de retrieval par similarité. Tu ne peux pas les éliminer en choisissant un meilleur modèle d'embedding, en ajoutant des dimensions, ou en fine-tunant. La pathologie est dans la structure même de l'espace.
Ce que ça change pour tes décisions d'architecture
Passer de BGE-base à BGE-large pour "plus de capacité" ne t'achète rien en termes de résistance à l'interférence. 768 ou 1024 dimensions nominales, tu restes à 16 dimensions effectives. Le compute d'indexation supplémentaire ne se traduit pas en fiabilité mémorielle.
Si tes hallucinations RAG augmentent avec la taille de ta base documentaire, c'est prévisible et mécanique. Plus de documents signifie plus de concurrents dans un espace à 16 dimensions effectives, donc plus d'interférence, donc plus d'oubli et plus de faux souvenirs. La géométrie explique ce que la qualité des embeddings ne peut pas corriger.
Les stratégies de mitigation qui marchent réduisent la compétition entre mémoires : chunking agressif, filtrage par métadonnées avant la recherche vectorielle, réindexation sélective des documents critiques. Ces techniques ont maintenant une justification théorique précise, au-delà du seul empirisme.
On avait creusé l'architecture mémoire pour agents dans cet article sur le 7B qui bat GPT-5.4 en deep research, et les vulnérabilités géométriques décrites ici expliquent une partie des échecs que ce type de système cherche à contourner. Si tu utilises un outil comme MemPalace, ces 16 dimensions effectives s'appliquent directement à l'espace dans lequel tes souvenirs locaux coexistent.
Un audit spectral de tes embeddings en production révèle tes vraies vulnérabilités à l'hallucination, bien au-delà de ce que les benchmarks classiques mesurent.