 @outsource_">
@outsource_">
Le modèle tourne en local, sans garde-fous, à 93.7% de compliance HarmBench, avec une régression MMLU de seulement -2%. Sur un Mac Apple Silicon avec 24 Go de RAM unifiée.
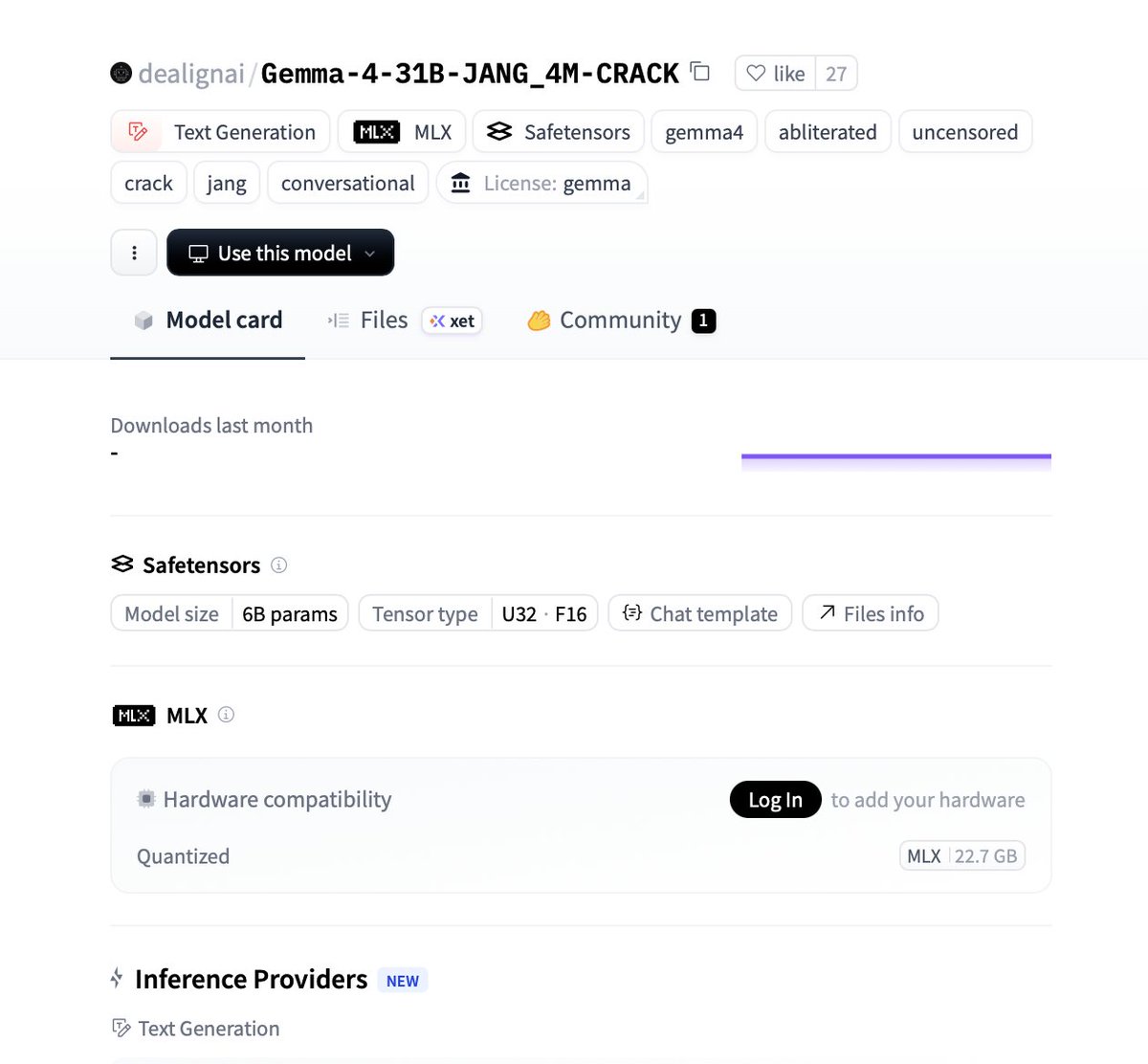
L'ablitération supprime directement les vecteurs de refus dans les poids du modèle. Le résultat ici : Gemma-4-31B-JANG_4M-CRACK par dealignai, 18 Go en mémoire, 22.7 Go sur disque.
Prérequis avant de commencer
Un Mac Apple Silicon avec 24 Go minimum de RAM unifiée. En dessous, le modèle ne charge pas. 32 Go si tu veux un contexte long sans swap.
LM Studio est à éviter pour l'instant : son backend MLX ne prend pas encore en charge Gemma 4 (bug actif au moment de la release). L'outil qui fonctionne est vMLX, version 1.3.26 minimum.
- 1
Télécharger le modèle depuis HuggingFace
Va sur dealignai/Gemma-4-31B-JANG_4M-CRACK. Le quant MLX pèse 22.7 Go sur disque. Tu peux le télécharger directement depuis l'interface HuggingFace ou viahuggingface-cli:huggingface-cli download dealignai/Gemma-4-31B-JANG_4M-CRACK \ --local-dir ~/models/gemma4-crack \ --include "*.safetensors" "*.json" "*.txt"Le dossier final doit contenir les fichiers de config et les shards du modèle.
- 2
Installer vMLX 1.3.26+
Télécharge vMLX depuis vmlx.net. L'app est pensée pour les quants MLX et charge Gemma 4 sans configuration supplémentaire.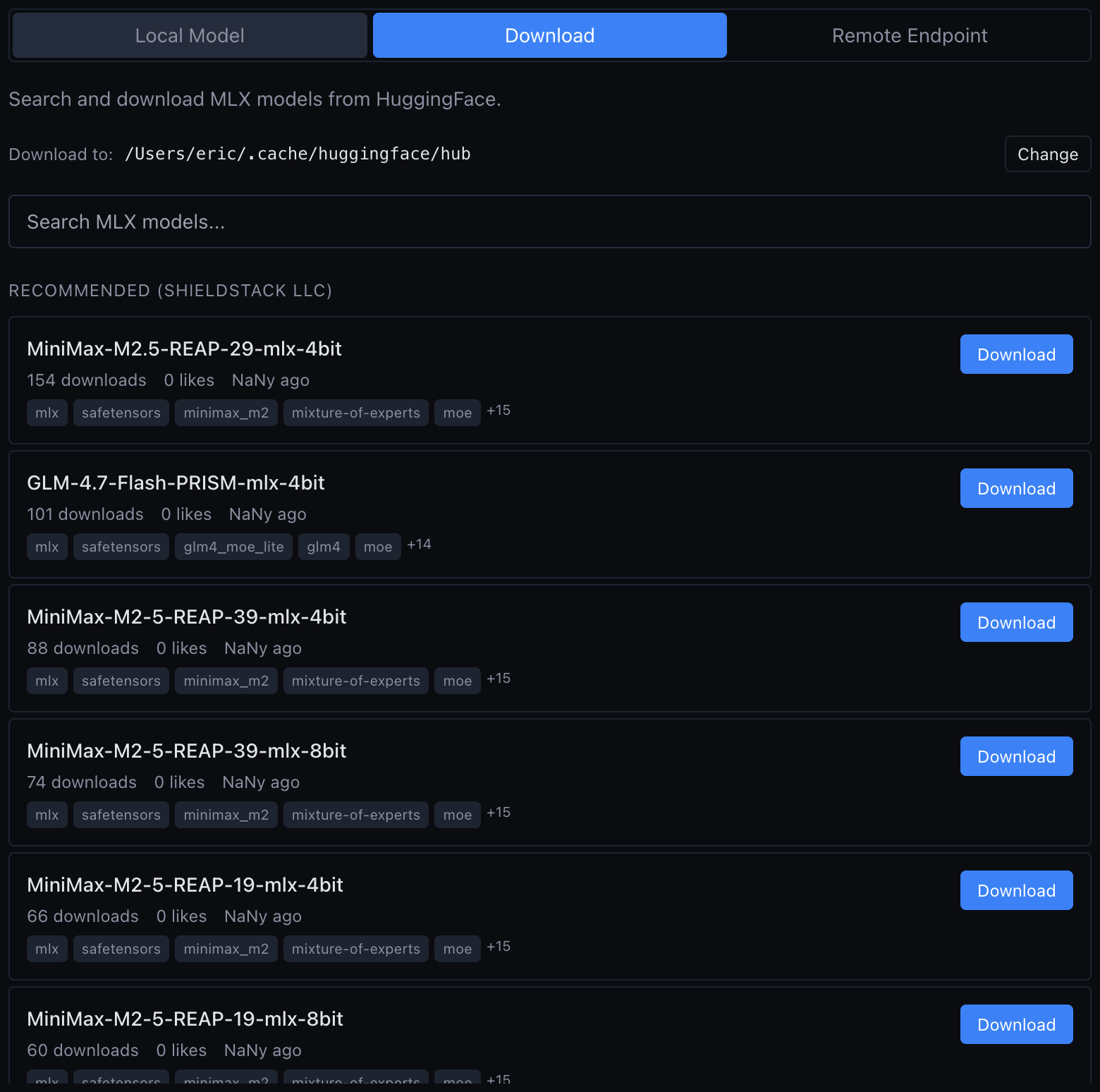
Une fois l'app ouverte, pointe vers le dossier local où tu as téléchargé le modèle. Le chargement prend 15 à 30 secondes selon la vitesse de ton SSD.
- 3
Lancer et configurer
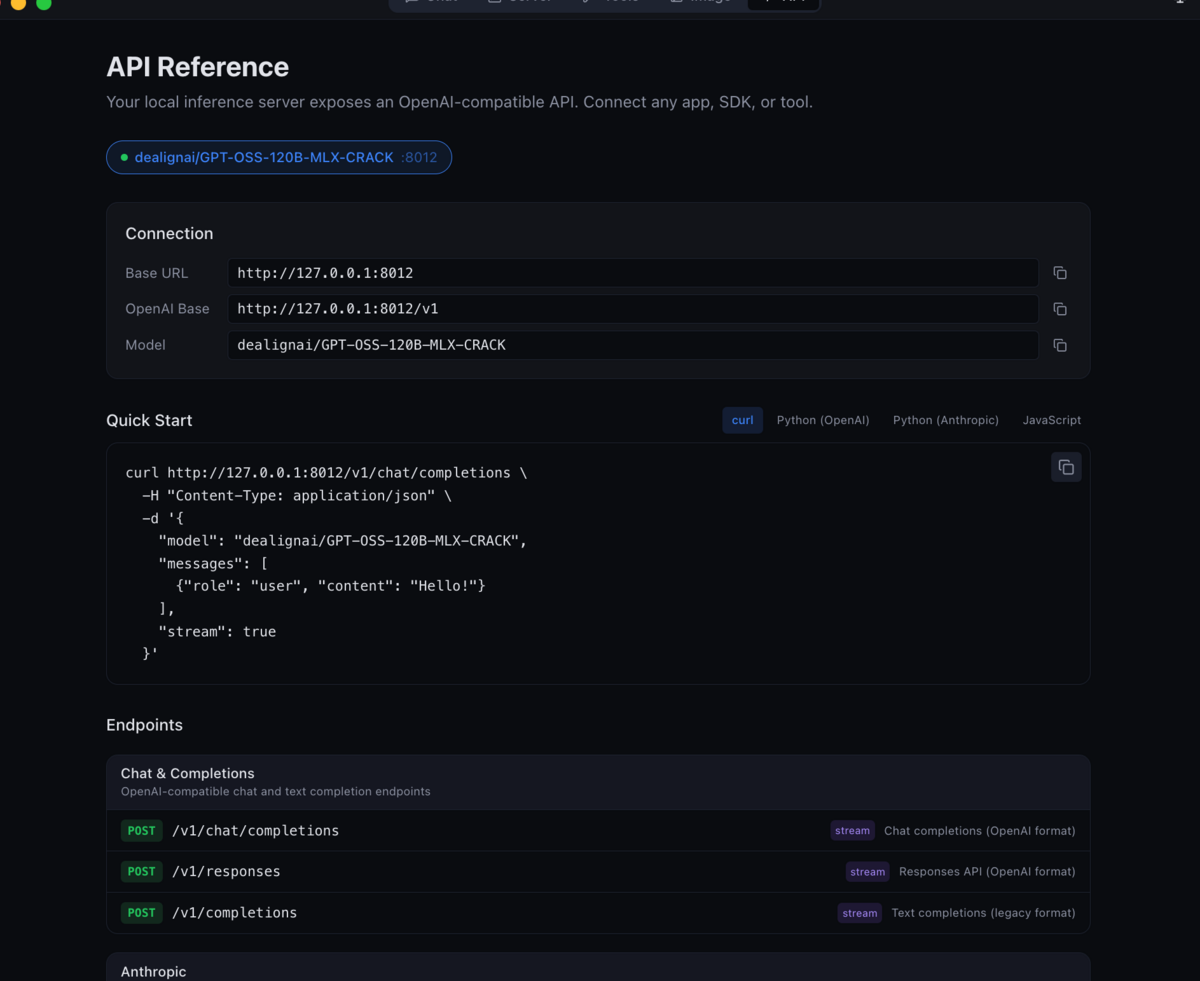
Dans vMLX, sélectionne le modèle chargé. L'interface expose un endpoint compatible OpenAI chat completions, ce qui te permet de le brancher à n'importe quel client qui parle ce format.
Pour tester en CLI directement :
curl http://localhost:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "gemma4-crack", "messages": [{"role": "user", "content": "Teste"}], "max_tokens": 200 }'Une réponse JSON avec un champ
choicesconfirme que le modèle tourne.
Ce que vMLX donne en plus
L'app embarque des outils agentiques built-in : file I/O, shell, web search via DuckDuckGo/Brave, et fetch d'URL.
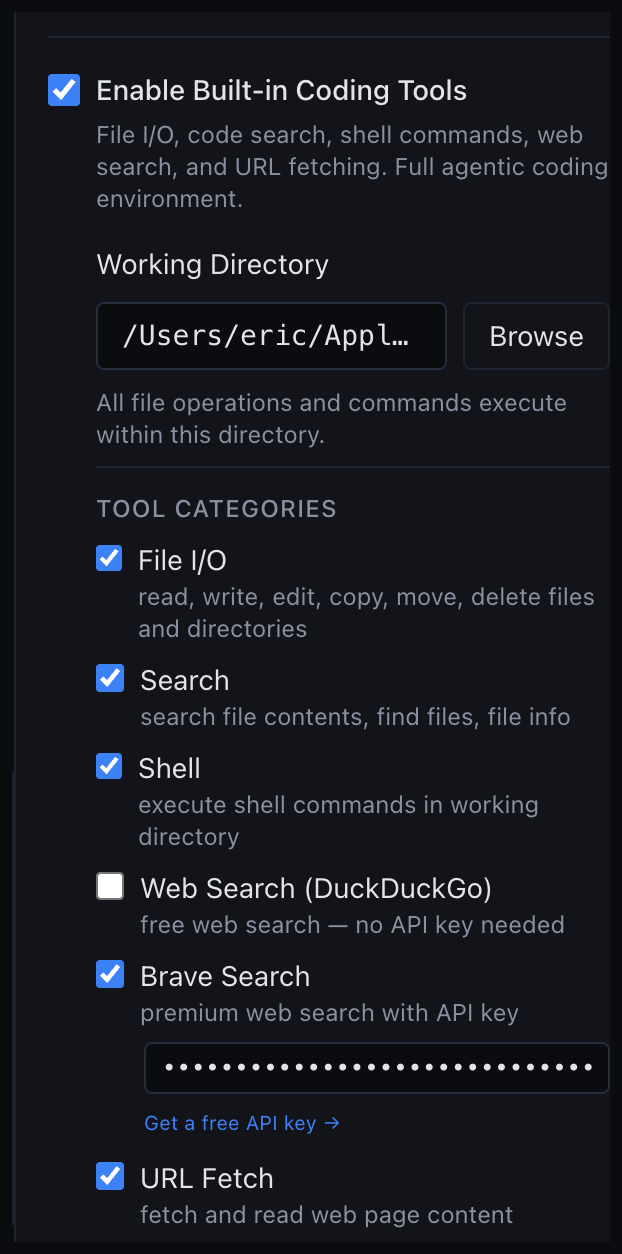
Sur un modèle ablitéré, ces outils combinés couvrent du red-teaming local ou de la recherche sans contrainte. L'API expose aussi les endpoints Anthropic Messages si tu préfères ce format.
Pour aller plus loin
Pour le sizing hardware en détail (contexte long, comparaison avec Qwen3 et Llama 4), Gemma 4 Guide est la ressource la plus complète disponible.
On avait creusé le trick mémoire unifiée AMD pour faire tourner des LLM locaux à 20 tok/s sur un mini PC à 350 dollars il y a peu. L'angle est différent, mais la logique de mémoire unifiée est exactement la même.
Formation
Intégrez LLM dans votre workflow
Workshop pratique sur vos cas d'usage. Pas de slides génériques — on build ensemble.
Communauté
Rejoins les builders IA
Tips, prompts, retours d'expérience. Le Telegram des gens qui buildent avec l'IA.


