
Un Qwen3 26B qui tourne à 20 tokens par seconde. Sur une machine de la taille d'une boîte à chaussures. À 65W. Sans cloud, sans abonnement, sans GPU dédié.
C'est ce que @basecampbernie a démontré sur son Minisforum UM790 Pro, et le setup est reproductible pour moins de 400$.
Ce qui rend ça possible n'est pas le CPU, ni un quelconque overclock. C'est l'architecture mémoire de l'iGPU AMD Radeon 780M, et la façon dont Vulkan contourne la limite BIOS pour accéder à la RAM système complète.
Pourquoi le 780M fait ce que les autres iGPU ne font pas
La plupart des iGPU Intel ou Nvidia ont une VRAM dédiée ou une allocation fixe. Le 780M n'a pas de VRAM du tout. Il pioche directement dans le pool DDR5 via mémoire unifiée, exactement comme un Apple Silicon.
Le BIOS affiche "4GB VRAM". C'est une limite logicielle, pas physique. Vulkan et le mécanisme GTT (Graphics Translation Table) peuvent allouer bien au-delà. Sur une config 64GB DDR5, @basecampbernie confirme 40GB accessibles au GPU, malgré un BIOS configuré à 16GB max.
Les modèles denses sur ce hardware restent en single digits. Ce qui débloque les 20 tok/s, ce sont les modèles MoE (Mixture of Experts) comme Qwen3 ou Gemma4 : seule une fraction des poids est activée par inférence, ce qui réduit drastiquement la bande passante mémoire nécessaire.
Le setup complet
Matériel :
- Minisforum UM790 Pro (349$ sur Amazon, barebones disponible si tu veux choisir ta RAM)
- 2x 32GB DDR5-5600 (64GB total, vitesse plus déterminante que la taille sur cette plateforme)
- 1TB NVMe pour les modèles
La RAM est le vrai levier. Plus elle est rapide, plus le 780M en profite : la bande passante DDR5 est le goulot d'étranglement, pas les compute units. Si tu cherches un ROI encore meilleur, l'AOOSTAR MACO470 arrive avec du DDR5-6400 et un port OCuLink pour un eGPU éventuel.
Logiciel :
Fedora Linux. Pas Windows. Sur Windows, l'iGPU est limité à 50% de la RAM système, soit 16GB sur 32GB installés. Linux + Vulkan lève cette contrainte et laisse GTT allouer jusqu'à 40GB.
Les étapes pour reproduire
Formation
Intégrez LLM dans votre workflow
Workshop pratique sur vos cas d'usage. Pas de slides génériques — on build ensemble.
- 1
Préparer le BIOS
Au démarrage, entre dans le BIOS et alloue le maximum autorisé au GPU (généralement 4 ou 8GB selon le firmware). Ce n'est pas le plafond réel, juste la valeur initiale que Vulkan va dépasser via GTT. Sauvegarde et redémarre sous Linux. - 2
Installer llama.cpp avec support Vulkan
Clone et compile avec le backend Vulkan activé :git clone https://github.com/ggerganov/llama.cpp cd llama.cpp cmake -B build -DGGML_VULKAN=ON cmake --build build --config Release -j$(nproc)Vérifie que Vulkan détecte bien le 780M :
./build/bin/llama-cli --list-devicesTu dois voir le Radeon 780M listé avec une VRAM reportée bien supérieure aux 4GB du BIOS.
- 3
Télécharger un modèle MoE quantifié
Les modèles denses ne passent pas à 20 tok/s sur ce hardware. Il faut du MoE. Deux options testées par la communauté :- Qwopus3.5-27B TurboQuant TQ3_4S : quantification TurboQuant spécifiquement optimisée pour hardware limité
- PolarQuant Gemma : collection Gemma4 quantifiée pour iGPU AMD
huggingface-cli download YTan2000/Qwopus3.5-27B-v3-TQ3_4S \ --local-dir ./models/qwopus-27b - 4
Lancer l'inférence avec offload GPU maximum
./build/bin/llama-server \ --model ./models/qwopus-27b/model.gguf \ --n-gpu-layers 99 \ --ctx-size 8192 \ --host 0.0.0.0 \ --port 8080Le flag
--n-gpu-layers 99force llama.cpp à offloader le maximum de layers vers le 780M. GTT prend le relais au-delà de l'allocation BIOS. Surveille la RAM système pendant le chargement : tu verras le GPU grignoter bien au-delà des 4GB affichés. - 5
Connecter à ton client ou agent
Le serveur expose une API compatible OpenAI surhttp://localhost:8080. Tu peux le brancher directement à n'importe quel client qui supporte une base URL custom : Open WebUI, Continue.dev, ou ton propre code.from openai import OpenAI client = OpenAI( base_url="http://localhost:8080/v1", api_key="local" ) response = client.chat.completions.create( model="qwopus-27b", messages=[{"role": "user", "content": "Hello"}] )

Formation
Intégrez LLM dans votre workflow
Workshop pratique sur vos cas d'usage. Pas de slides génériques — on build ensemble.
L'autre point à ne pas rater : le choix du modèle. Un Llama 3 dense en Q4 sur ce hardware tourne entre 4 et 6 tok/s. Utilisable, mais loin des 20 tok/s. Passer aux MoE n'est pas une optimisation, c'est une condition.
Formation
Intégrez LLM dans votre workflow
Workshop pratique sur vos cas d'usage. Pas de slides génériques — on build ensemble.
Ce que ça donne dans la pratique
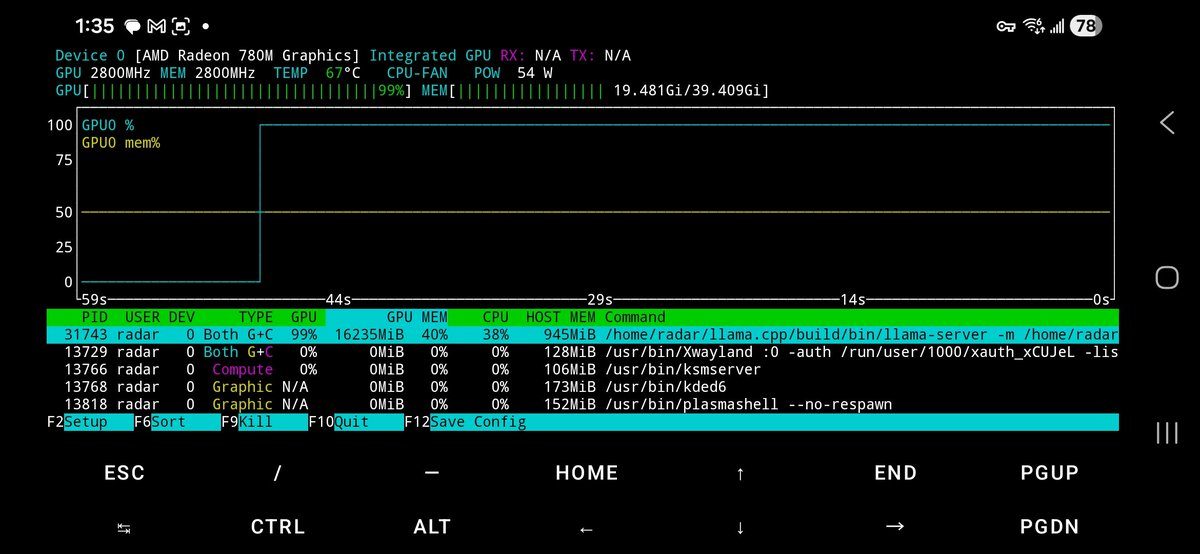
20 tok/s dépasse la vitesse de lecture confortable d'un humain. En mode chat, la latence perçue est nulle. En mode agentic avec web search, @basecampbernie note que les petits modèles "find what they don't know" : ils n'ont pas besoin de 100GB de poids sur l'histoire du monde si tu leur donnes accès à une recherche. Un Qwen3 26B en boucle agentic sur ce setup bat en pratique un modèle plus lourd qui tourne à 3 tok/s.
La consommation à 65W représente environ 570 kWh/an en 24/7, soit 80-100€ d'électricité selon ton tarif. À comparer avec n'importe quel abonnement API.
Modèle 27B quantifié avec l'algorithme TurboQuant, optimisé pour hardware à mémoire unifiée limitée.
Communauté
Rejoins les builders IA
Tips, prompts, retours d'expérience. Le Telegram des gens qui buildent avec l'IA.


